





La semana pasada ya dabamos un preámbulo sobre este tema y en esta oportunidad vamos a seguir profundizando. Desde una perspectiva analítica, la minería de datos es un reto debido a la gran disparidad de problemas y tipos de datos que se encuentran.


Por ejemplo, un problema de recomendación de productos comerciales es muy diferente de una aplicación de detección de intrusos, incluso a nivel del formato de los datos de entrada o de la definición del problema. Incluso dentro de las clases de problemas relacionados, las diferencias son bastante significativas.
Otro caso sería, un problema de recomendación de productos en una base de datos multidimensional es muy diferente de un problema de recomendación social debido a las diferencias en el tipo de datos subyacentes. Sin embargo, a pesar de estas diferencias, las aplicaciones de minería de datos suelen estar estrechamente relacionadas con uno de los cuatro superproblemas de la minería de datos:
- La minería de patrones de asociación,
- La agrupación,
- La clasificación y
- La detección de valores atípicos.


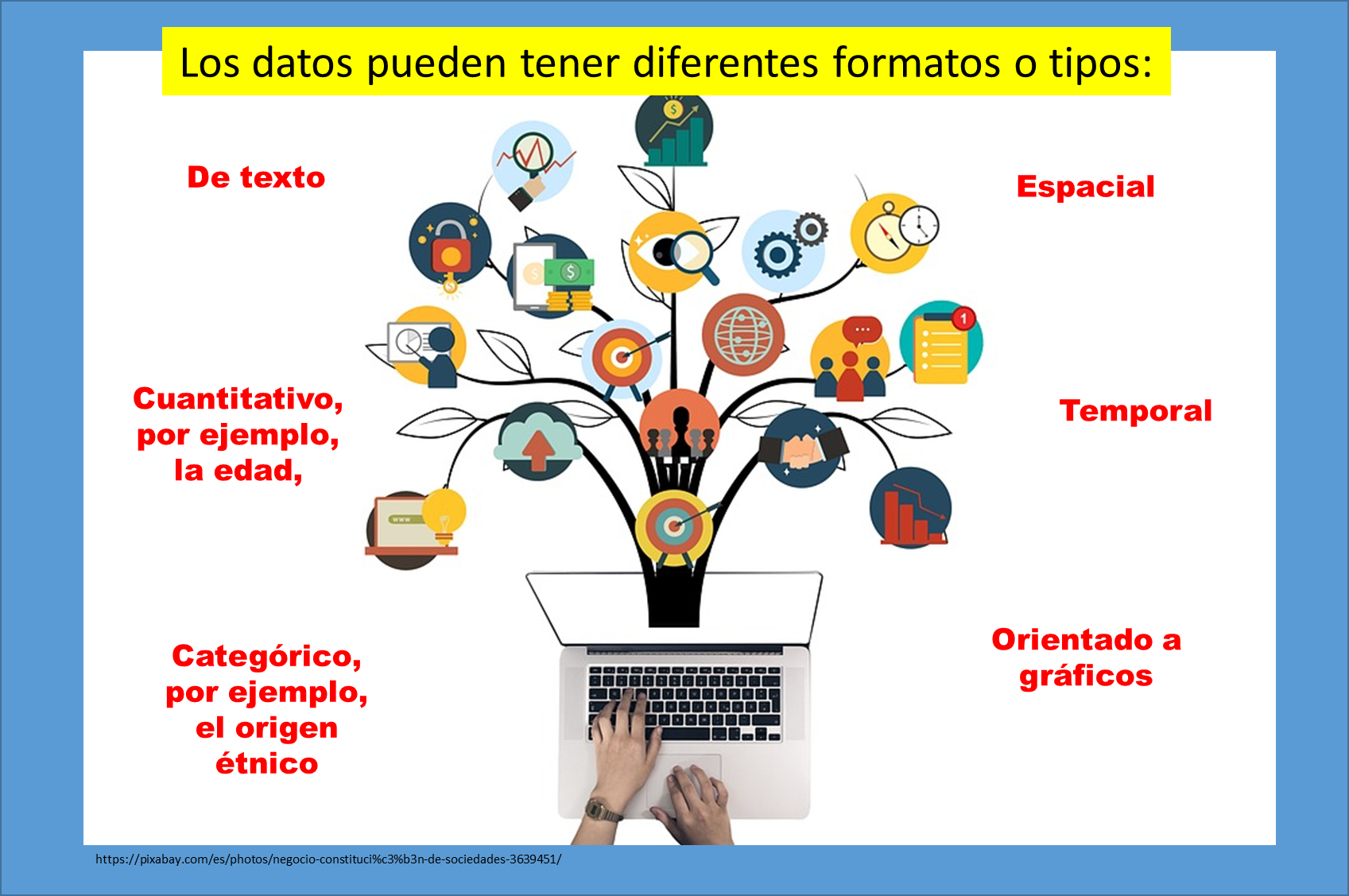
Aunque la forma más común de datos es la multidimensional, una proporción cada vez mayor pertenece a tipos de datos más complejos. Aunque existe una portabilidad conceptual de los algoritmos entre muchos tipos de datos a un nivel muy alto, no es así desde una perspectiva práctica.
La realidad es que el tipo de datos preciso puede afectar al comportamiento de un algoritmo concreto de forma significativa. Como resultado, uno puede necesitar diseñar variaciones refinadas del enfoque básico para datos multidimensionales, de modo que pueda ser utilizado eficazmente para un tipo de datos diferente.
En los últimos años se ha planteado un gran reto debido al aumento del volumen de datos. La prevalencia de los datos recogidos continuamente ha provocado un interés creciente en el campo de los flujos de data.
Por ejemplo, el tráfico de Internet genera grandes flujos que ni siquiera pueden almacenarse eficazmente a menos que se destinen importantes recursos al almacenamiento. Esto conlleva retos únicos desde el punto de vista del procesamiento y el análisis. En los casos en que no es posible almacenar explícitamente los datos, todo el procesamiento debe realizarse en tiempo real.
Como cientifico uno de los objetivos es el de estudiar la minería de datos desde la perspectiva de diferentes abstracciones de problemas y tipos de datos que se encuentran con frecuencia. Muchas aplicaciones importantes pueden convertirse en estas abstracciones.




El diseño final de una solución para un problema concreto de minería de datos depende de la habilidad del analista a la hora de asignar la aplicación a los distintos bloques de construcción, o de utilizar algoritmos novedosos para una aplicación específica.

Para Cervantes Ciencia, escribió @abdulmath ¡Me encuentras en Hive!


¿Sabías que el ascensor es más antiguo de lo que crees? Pues sí, de hecho las primeras versiones de vapor fueron desarrollados a mediados del siglo XIX.



Nuestra cuenta @cervanteshive está bastante activa en la red social de este pajarito. Te invitamos a mantenerte informado sobre nuestra colmena Hive y el mundo de las criptos. ¡Únete y participa!
